







Google ha annunciato il lancio di Gemma 2, l’ultima iterazione della sua famiglia di modelli linguistici open source (a differenza dei modelli Gemini). Questa nuova versione del modello Gemma offre prestazioni migliorate e un’efficienza senza precedenti. Gemma 2 è stato progettato per essere accessibile a ricercatori, sviluppatori e appassionati di tutto il mondo, democratizzando l’accesso a tecnologie IA all’avanguardia. In questo articolo, presentiamo le caratteristiche principali di Gemma 2 e le sue potenziali applicazioni.

Caratteristiche principali di Gemma 2
Sviluppato da Google DeepMind e da altri team dell’azienda, questo nuovo LLM ha la base la stessa ricerca e tecnologia utilizzata per creare i modelli Gemini.
Gemma 2 si distingue per diverse caratteristiche innovative che lo rendono un modello linguistico di grande interesse per la comunità dell’IA. Innanzitutto, è disponibile in due dimensioni: 9 miliardi (9B) e 27 miliardi (27B) di parametri.
Questa flessibilità permette agli sviluppatori di scegliere la versione più adatta alle loro esigenze specifiche, bilanciando potenza e risorse computazionali richieste. Il modello da 27B è stato addestrato su 13 trilioni di token; invece la versione da 9B su 8 trilioni, al fine di garantire un’ampia conoscenza e capacità linguistiche.
Una delle innovazioni più significative di Gemma 2 è la sua architettura riprogettata; offre prestazioni superiori con una struttura più leggera. Google afferma che il modello da 27B può competere con modelli che hanno più del doppio dei suoi parametri; un’efficienza notevole. Inoltre, Gemma 2 è stato ottimizzato per l’inferenza rapida su diverse piattaforme hardware. Dalla potente NVIDIA H100 Tensor Core GPU ai laptop da gaming e desktop di fascia alta.
Un altro aspetto cruciale di Gemma 2 è la sua efficienza in termini di costi. Il modello può essere implementato su un singolo host TPU di Google Cloud o su GPU NVIDIA di ultima generazione; una riduzione dei costi di implementazione notevole rispetto ad altri modelli di dimensioni simili. Questa caratteristica rende Gemma 2 particolarmente attraente per startup e ricercatori con budget limitati.
Prestazioni
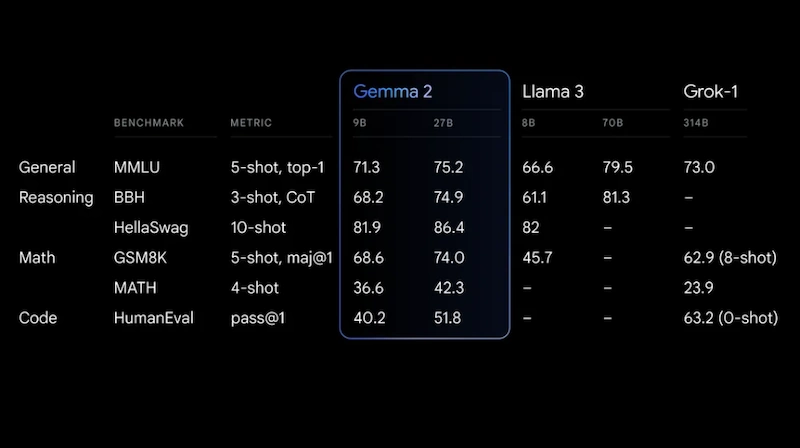
In termini di prestazioni, Gemma 2 si distingue in vari benchmark. Il modello da 9B supera le prestazioni di Llama 3 8B e altri modelli open source di dimensioni simili; invece la versione da 27B offre prestazioni paragonabili a modelli molto più grandi come Mixtral 8x22B. Queste prestazioni dimostrano l’efficacia delle innovazioni tecniche implementate in Gemma 2.
Gemma 2 è progettato per essere versatile e adattabile a una vasta gamma di applicazioni nel campo dell’intelligenza artificiale. Grazie alle sue capacità avanzate di elaborazione del linguaggio naturale, il modello può essere utilizzato per vari compiti; automazione del servizio clienti, creazione di contenuti, strumenti educativi, analisi dei dati e reporting, sviluppo di assistenti virtuali, ricerca e sviluppo.
La versatilità di Gemma 2 lo rende uno strumento prezioso per una vasta gamma di industrie e settori; dal tech alla sanità, dall’educazione alla finanza. La sua capacità di essere facilmente adattato e fine-tuned per compiti specifici lo rende inoltre particolarmente attraente per le aziende che cercano di implementare soluzioni IA personalizzate.
Accessibilità e integrazione
Uno degli aspetti più rilevanti di Gemma 2 è la sua accessibilità. Entrambi i modelli LLM (large language model) sono già disponibili per essere provati su Hugging Face, Kaggle, Google Vertex AI, JAX, PyTorch e TensorFlow tramite Keras 3.0 nativo. Questa ampia compatibilità permette agli sviluppatori di utilizzare Gemma 2 con i loro strumenti e flussi di lavoro preferiti; l’adozione e l’implementazione del modello in progetti esistenti è molto più facile.
Per facilitare ulteriormente l’uso di Gemma 2, Google ha collaborato con partner come NVIDIA per ottimizzare il modello per l’infrastruttura accelerata NVIDIA. Gemma 2 è ottimizzato con NVIDIA TensorRT-LLM per funzionare su infrastrutture accelerate NVIDIA o come microservizio di inferenza NVIDIA NIM. Queste ottimizzazioni garantiscono che gli sviluppatori possano sfruttare appieno le capacità hardware disponibili per massimizzare le prestazioni di Gemma 2.
Come nel modello precedente Gemma 1.0, entrambe le dimensioni del modello saranno disponibili con una licenza commerciale (per esempio in ambito IoT); indipendentemente dalle dimensioni dell’organizzazione, dal numero di utenti e dal tipo di progetto. In ogni caso Google ammette solo usi leciti della sua LLM open source.
Google ha anche reso disponibile Gemma 2 attraverso Google AI Studio; questo permette agli sviluppatori di testare le capacità complete del modello da 27B senza requisiti hardware specifici. Questa piattaforma offre un ambiente user-friendly per sperimentare con Gemma 2 e sviluppare applicazioni basate su di esso.

Sicurezza e sviluppo responsabile dell’IA
Google ha posto una forte enfasi sulla sicurezza e sullo sviluppo responsabile dell’IA nella creazione di Gemma 2. Il modello è stato sottoposto a rigorosi processi di filtraggio dei dati di pre-addestramento e a test e valutazioni approfondite per identificare e mitigare potenziali pregiudizi e rischi.
Per supportare gli sviluppatori nell’uso responsabile di Gemma 2, Google ha rilasciato il Responsible Generative AI Toolkit. Questo toolkit include strumenti come LLM Comparator, che aiuta gli sviluppatori a condurre valutazioni comparative approfondite dei modelli linguistici. Google sta anche lavorando per rendere open source la sua tecnologia di filigrana del testo, SynthID, per i modelli Gemma; un ulteriore livello di trasparenza e tracciabilità.
Durante l’addestramento di Gemma 2, Google ha seguito rigorosi processi di sicurezza interni, valutando il modello su un set completo di metriche relative alla sicurezza e ai danni rappresentativi. I risultati di queste valutazioni sono stati pubblicati su un ampio set di benchmark pubblici.
Come eseguire Gemma sul tuo computer
Puoi eseguire il LLM di Google localmente su laptop e desktop, su dispositivi IoT, dispositivi mobili e cloud. Se vuoi eseguirlo su Desktop o laptop puoi utilizzare LM Studio, ollama, GPT4ALL, chatllm, Faraday.
LM Studio ha già inserito Gemma 2 tra i suoi modelli disponibili e può essere installato direttamente dalla GUI LM Studio.
L’uso di LLM locali come Gemma 2, richiedono un hardware sufficientemente potente e adeguato. La RAM del pc parte da un minimo di 16GB, ma quantità anche notevolmente maggiori (128GB) permettono veloci tempi di risposta e l’uso di LLM di dimensioni maggiori.
Per eseguire Gemma (2B o 7B) sono sufficienti 16 GB di RAM.
La VRAM della GPU dovrebbe essere almeno 8GB. Anche le CPU con capacità IA (NPU integrata) possono accelerare notevolmente il processo di elaborazione rispetto una CPU senza funzionalità IA.
Gemma 2: conclusioni
Gemma 2, con le sue prestazioni, l’efficienza e l’accessibilità migliorata, ha il potenziale per accelerare l’innovazione nell’IA e democratizzare l’accesso a tecnologie avanzate di elaborazione del linguaggio naturale.
La capacità del modello di funzionare efficacemente su una varietà di hardware, dai potenti GPU ai laptop di fascia alta, lo rende una risorsa preziosa per sviluppatori, ricercatori e appassionati con diverse esigenze e vincoli di risorse.


